I would like to suggest to the Unicode community the following observations relating to the Unified Canadian Aboriginal Syllabics range. My goal (see www.languagegeek.com) is to enable all of the North American languages to be properly and accurately written on the Internet, and computers in general. Here I will focus specifically on the languages which are currently using or historically used (and may still be in some communities) syllabics.
Some conventions used below. All Unicode character names are in majuscule, and “Canadian Syllabics” has been abbreviated to CS. Hexadecimal Unicode indices are in parentheses and prefixed with “U+”. All sources cited are linked to the languagegeek.com bibliography. A “final” is the Syllabics term for a character which represents a consonant only, not a consonant + vowel, so CS FINAL GRAVE (U+1420), CS CARRIER H (U+144B) and CS NASKAPI SKW (U+150A) would all be examples of “finals”. I use the term “syllabic” to refer to a consonant + vowel character. A series is a row of characters on a syllabic chart, so in Misnamed Characters Note 1, “tta, tte, tti, tto” would be the tt-series.
Characters that perhaps should be discontinued.
- The asterisk ᕯ character (U+156F)
appears on the code-page chart as **, and is named CS TTH. This is a misreading of the syllabarium chart used by the French
Missionaries for Chipewyan—probably from the 1904 publication
Prières
Catéchisme et Cantiques en langue Montagnaise ou Chipeweyan. The chart
in this book has been reprinted in most if not all “scripts of the world”
type books. The relevant excerpt from the chart is shown below.

Unlike most other syllabics charts, this one does not have a column of finals to the right of the consonant-vowel syllabics. Instead, it simply has a list of all the finals, which do not correspond with the syllabics series on the same row. Thus, the CS WEST-CREE P (U+144A) (looks like a prime ') final which appears to the right of the “tta” row is not the sound “tt”, but is instead “h”. The blue circled asterisk is not “tth”, but is in fact a symbol which indicates a proper name, in this case /*adą/ (Adam). A second glitch on the Unicode code-page chart is that this character is written with two asterisks “**”, when in fact on the chart above, the first asterisk is the character itself, and the second is part of the example. I believe this should definitively be fixed.
Missing Characters
Blackfoot
- In Blackfoot, a raised “equals sign” is used much as the “CS FINAL
MIDDLE DOT” (U+1427) is in Cree: to indicate a /w/ between the consonant
and vowel of the syllabic. In the graphic below, the red arrow is pointing
to this character, which in combination with the “CS BLACKFOOT KA”
(U+15BD) before it, gives the sound /kwa/. This character is vital to
writing Blackfoot, should be added. This example taken from
Stockten 1888.

Carrier Dene
- A few finals are missing from Unicode which are used in Carrier.
Information for Carrier is from
Poser
2000. There is an important graphical distinction between the finals
used for /s/ and /s/ (in the Roman Orthography version). The former
is a small serif “s” written mid-line, while the latter is a
small sans-serif “s” (with a flat top and bottom line) written
mid-line. This is exemplified below by the blue circle (from
Morice 1894). Unicode lists only one version (U+1506) CS ATHAPASCAN S. A second character, an upside-down
mid-line small “h” is used for load words with /f/ or /v/ sounds. The
second example below is /ave/. These two finals should be added.

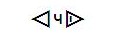
- In examples of Carrier, the finals are virtually always mid-line. This
is purely stylistic, but see Dene note 2 about how final placement is
phonetically important. This example is from
Morice 1894, note that all of the finals are mid-line, not top-line as
in Unicode.

Dene (Chipewyan, Slavey, Hare, Beaver)
- In early Chipewyan texts (the example below is from
Kirkby 187.), a-finals—like those used in Eastern dialects of
Cree—were used instead of the western-finals which were employed in all
later Chipewyan texts. For the most part, Unicode includes these finals
under names such as CS K (U+1483), however, some of the Chipewyan series
are not to be found in Cree, and are thus absent. The two missing finals
are shown in the graphic below. The blue arrow indicates a raised small
version of CS WEST-CREE LA (U+154D). The red arrow points to a raised /ga/
syllabic. The g-series here corresponds to CS SAYISI HE, HI, HO, HA
(U+15C0–15C3). Though no longer used today, for historical purposes, these
characters may be added.

- In Dene texts, it is vitally important to distinguish between the
position of the finals, top-line, mid-line, or bottom-line. The same shape
character may have a completely different value depending on how high up
from the baseline it is. In the first example below (from
LeGoff 1890), the red arrow shows the top-line Chipewyan character
which resembles CS WEST-CREE M (U+14BC). The blue arrow points to a
mid-line version of the same shape. The top-line is a diacritic which
indicates that the following sound (the mid-line “s”) is pronounced /ł/
instead of /l/ if the top-line diacritic were missing. The mid-line
version has the sound /m/.
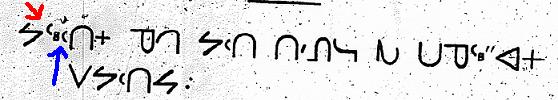
Both these characters are exemplified on the graphic shown below (from Perrault 1865). The red arrow points to the top-line final, in the word /łue/ “fish” where the diacritic changes the /l/ sound into /ł/. The blue arrow indicates the mid-line final /m/, in the word /abraam/ “Abraham”. If the mid-line final were top-line, as is CS WEST-CREE M (U+14BC), it would be pronounced /*abraax/. The green arrow shows the mid-line version “prime” <'> pronounced /b/ in Dene. If the final were top-line, it would be representing an /h/ sound, giving an incorrect reading of /haraam/.
Both of the examples above come from the Syllabic tradition instigated by French Catholic Missionaries. The English Anglican style of writing Dene is different in some important ways. With regards to final placement, where the French system distinguishes top- and mid-line finals, the English differentiate between top- and bottom-line. In the first example below, from
a South Slavey text (Reeve 1900), the red arrow shows a top-line character like CS C (U+14A1), whereas the blue indicates the base-line variety. When at the top, finals in the Anglican tradition are diacritics modifying the following sound (much like the Catholic examples above). So, a top-line CS C is combining with the following CS WEST-CREE LE (U+1544) to produce /tli/ (where /tl/ is a single phoneme). The base-line final is /t/ alone.

This system holds true with other finals as well. Below, from Kirkby 1881c, the base-line version of CS SAYISI TH (14A2) is shown, which is a final pronounced /th/ or /dh/.
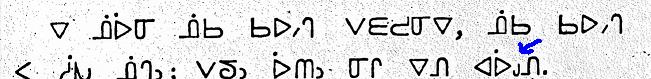
The next example (from the same book), has a top-line CS SAYISI TH, which combines with the following syllabic CS WEST-CREE LA (U+154D); together they sound like /ła/. If the top-line CS SAYISI TH were written at the baseline, the sound would be /thla/ or /dhla/. Moreover, if in the above example, the baseline CS SAYISI TH were at the top-line, instead of /thli/, the sound would be /łi/.

These examples should make it clear that the Dene Syllabics system distinguishes top-line from mid-line and baseline finals in very important ways. I have not included all of the characters which can change position to make different phonemes (but I could if necessary). As for how to render this in Unicode, I see two possibilities.- Encode three unique characters for each final, i) top-line, ii) mid-line, iii) baseline. First, this solution is not terribly encoding-efficient. Also, it sets up different encodings for glyph variants of different styles. For example, some Cree fonts place the CS FINAL RING (U+1424) at the top-line, others at mid-line. This differentiation should be based on the font, not on Unicode encoding. An opentype substitution would be a much better solution for stylistic differences I think
- Add three non-spacing “characters” to the UCAS range, which tell the software where to put the final: top, mid, or base. This also allows much more flexibility for writers who want control over how high up their finals reside.
- The graphic directly above has a green arrow pointing to an accented CS THA (U+1566). This accent can be either acute or a tilde (depending on the font). It appears in extremely limited contexts (in my data, always above CS THA, for the postposition meaning “with”). I don’t believe a series of pre-composed accented syllabics is required, however, a non-spacing CS ACCENT would be sufficient. Note that using COMBINING ACUTE ACCENT (U+0301) and COMBINING TILDE (U+0303) may not be a good solution, as in Dene, there is no real orthographical difference between acute and tilde (much like Greek tilde and reverse-breve). Beaver also has the accent, but it does not appear above the syllabic, instead it shows up after the syllable (looking exactly like CS FINAL ACUTE [U+141F], which I believe suffices to represent the Beaver acute), and much more frequently. I do not have data as to what the Beaver acute represents phonologically.
- As can be seen from the Dene examples above, these languages also use the dot accent diacritic, although not to mark long vowels. In Chipewyan (English tradition) and South Slavey, a dot on an o-vowel syllabic changes the vowel to “u”. While in Beaver, a dot over an a-vowel syllabic is pronounced as a “y” off-glide to the vowel. Although these characters and others should have unique Unicode encodings to be consistent with the rest of the UCAS range, if there is a non-spacing dot diacritic, this ought to suffice.
Ojibway
- Several dialects of Ojibway in Northern Ontario have a unique means of
writing finals. It follows the logic of the Eastern finals (a small
top-line version of the a-syllabic), but instead it employs the i-version
of the syllabic. The
example below, points out several i-series finals.

The first blue arrow is the i-final version of CS C (U+14A1), the second is of CS K (U+1483), the third is of CS SH (U+1525), and the last is of CS N (U+14D0). The red arrow points out the CS GLOTTAL STOP (U+141E) which already exists in Unicode. The full list of i-finals is below. The top row contains the i-finals, the bottom row the a-final equivalents. The entire series of i-finals should be added to Unicode.
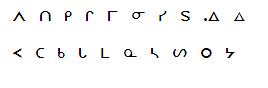
- Some dialects of Ojibway use the raised “l” and “r” finals (U+14EB and
U+1551) as distinct characters, while others place these above an n-series
syllabic as a diacritic. Two non-spacing characters would be required to
accommodate this.

Cree
- The UCAS code-chart incorrectly labels U+141E as a Moose Cree (Y). In
fact, the Moose Cree y-final is a small ring diacritic located above the
syllabic character. The Inuktitut characters like CS AAI (U+1402) and CS
PAAI (U+1430) would be read /iy/ and /piy/ in Moose Cree. The following
graphic, from
Ellis 1983, displays this diacritic clearly atop CS SHA (U+1515),
marked by the red arrow.
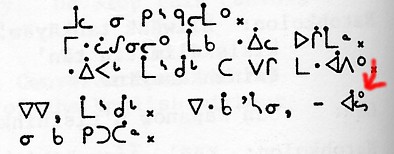
To be consistent, Unicode would have to encode a large number of pre-composed glyphs of a Moose Cree syllabic with the y-ring on top—not to mention those in combination with CS FINAL MIDDLE DOT (U+1427). Instead, perhaps a y-ring non-spacing diacritic would be useful. But U+141E is not a Moose Cree y. Some speakers prefer to place the small ring not above the syllabic character, but to the right like other finals. This small ring is also absent from Unicode, and should be included. This small ring should not be confused with the larger CS FINAL RING (U+1424), which in the example above appears just to the left of the tail of the arrow. - The Woods Cree dialect (labelled by Unicode as TH-Cree, U+15A7–U+15AE)
does not use an Eastern-style, raised a-final, as shown in U+15AE. To my
knowledge, U+15AE would not be used by anyone. The final I have seen used
(from the La Ronge Cree community) is missing from Unicode. The red circle
indicates the final. This character is required to write this dialect of
Cree.
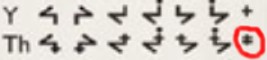
- I am curious to know why the n-series of Cree syllabics (U+14C0–14D2)
is missing half of the w-dot characters, namely: nwi, nwii, nwo, nwoo
(both eastern and western versions).
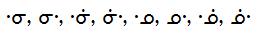
- For Y-Cree, please see note 2 under Questions below.
All languages:
- The correct form of the hyphen in Syllabics is a shortened equals
sign, the example below is from the same Ojibway text mentioned above.
Should this hyphen get its own Unicode encoding? A regular equals sign
doesn’t necessarily look right, and will not wrap properly. I single dash
hyphen is unacceptable because it would conflict with CS FINAL SHORT
HORIZONTAL STROKE (U+1428).

Questions
There are several questions I have about certain characters in the UCAS range.
- I mentioned above that there are several diacritics which perhaps should be non-spacing diacritics. Is it wise to use the standard Roman orthography non-spacing range? Or should different scripts have their own accentuation (like Greek does).
- What is the source for U+141D CS Y-CREE W. In Y-Cree dialects, the
final “w” is U+1424 CS FINAL RING. In some dialects of Y-Cree, the y-final
is a smaller top-line small dot instead of the CS WEST-CREE Y (U+1540).
This small top line dot combines with the CS FINAL MIDDLE DOT (U+1427) to
end up looking like a colon. The example below is from the book
Kātāayuk.
Is U+141D supposed to represent this character?

- Would anybody know the sources used for the characters referenced as “Sayisi”? I am completely unaware of certain characters, such as U+14BE, U+14BF, U+1541. In general, the Sayisi characters match the English-tradition Dene syllabics (as one would expect), but I have never come across the three characters above.
- Why are CS FWAA (U+155A–B), CS THWAA (U+1567–8), and CS RWAA (U+154E–154F) part of UCAS? What about “fwe, fwi, fwii, fwo, fwoo, fwa”, “thwe…”, and “rwe…” (both eastern and western versions)? Why do the long ā glyphs merit inclusion? I guess that someone was reading directly off a syllabics chart, not realising that the 6 glyphs above were just examples of entire series. It would have been more useful to include mid-dot syllabic composed characters for CS TH-CREE THE… (U+15A7–D), these th-cree th syllabics being in common use, where CS F…, CS TH…, and CS R…, are for load words only in Cree. Furthermore, perhaps a combing “mid-dot” would be useful for those syllabics which were not encoded as composed characters: e.g. “fwe”. Using CS FINAL MIDDLE DOT (U+1427) plus the syllabic character (in this case, CS FE [U+1553]) would not space properly.
- In some Dene systems, super script F, V, r, and l are used as finals to indicate these sounds from European languages. Carrier Dene also uses a regular roman “r” for loan words. Should these be encoded in UCAS? Are they still technically Roman glyphs?
That’s about all I can think of at the moment, there may be a few other issues I have temporarily forgotten. I would appreciate comments and suggestions as to how some or all of these ideas can be integrated into the Unicode Standard. All of the missing characters above can be found in the Aboriginal Serif font, which can be downloaded from this site. It is a free font (although the hinting on the syllabics is a bit off). Other Syllabics fonts will be available on this site in the future. My apologies if any of these issues have previously been discussed on this or other fora.
Chris Harvey
www.languagegeek.com